研究方向
色彩與照明科技領域
- 全方位色彩外貌視覺系統:包括明視覺、介視覺、暗視覺,在實際空間或虛擬實境中之物體表面色彩外貌評估
- 高動態影像顯示及其色彩管理技術
- 色彩情緒及色彩醒目度之心理物理學模型
- 色彩調和(美感配色系統)與視覺舒適度在各種場域之應用系統,包括視覺傳達設計、服裝設計、室內照明設計等
- 2D及3D之色彩視覺系統:包括靜態、動態影像、3D影像等視覺評估
- 2D及3D影像品質優化系統
- 3D顯示系統對心理及生理健康及安全之影響
- 高速3D掃瞄系統:包含快速3D足型掃瞄器、牙科專用3D掃描器,可快速精密測量不同差異之足型與牙齒尺寸,發展客製化之商品與診療
- 整合於3D列印之色彩外貌之複製重現技術:包含擬真的擷取物體色外貌,建立標準材質資料與輸出逼真之物體
- 白光源與彩色光源之測量與品質評估
- LED光源在室內與室外的優化設計
- 特殊LED光源:增加工作效率及增進生理機能
- 高演色性及節能之光源設計
此外,本所致力於技術移轉並開發具有潛力之高科技產品,包括以下項目:
- 影像顯示品質優化系統: 能夠對不同尺寸與解析度的顯示器 (含TV、手機、投影機、電子書) 經過畫質分析,優化顯示效果的一套系統
- 物體整體表面性質量測與模擬系統: 對各種不同的材質做2D至3D量測,透過光影與幾何角度的分析量測出整個物體的色度、光澤度、透明度、紋理、深度等參數,並考慮人因視覺特性,建立仿真的模擬影像,提供跨國工商設計一個不需要耗時郵寄樣品的綠色節能視覺模擬環境
- 人因照明分析系統: 經由2D量測場景光色分佈與人因資料庫連結推測人們處於這種照明環境下的短期與長期感受
- 情境智慧照明系統: 將照明特性與人因反應連結,提供能夠自動調整人們情緒與工作效率的智慧型LED照明系統
- 適合老人和弱視者 (low vision) 用途的照明與顯示系統: 因應人口老化,提供健康與安全的照明與顯示系統
- 醫學影像的應用: 使醫學影像重建後更接近真實 (例如MRI影像之色彩重建,牙醫工程之齒白重建) 以及色覺異常者之色覺檢測工具,並可利用多頻譜攝影技術改進病情診斷正確度
- 高速與高精確度3D掃描機:使得擷取3D資料更快速更容易,並適應未來高度客製化商品與資料分析之需求,如客製化製鞋、3D線上檢測、數位牙醫等
人工智慧應用領域
基於卷積神經網絡的瞳孔尺寸預測技術
瞳孔的大小或變化的速度可以同時表明其身體狀況和精神狀態。如果瞳孔收縮或瞳孔反應速率異常,則可能意味著一些症狀,例如青光眼、糖尿病性視網膜病、全身麻醉或霍納綜合症。另一方面,瞳孔的擴張可能受到精神條件的刺激,例如興奮和愉悅,而瞳孔的收縮可能是由於壓力、不適等引起的。本研究提出了一種基於卷積神經網絡(CNN)的可計算瞳孔大小的算法。通常,瞳孔的形狀不是圓形的,約50%的瞳孔可以使用橢圓計算獲得最佳擬合效果。本研究使用橢圓的長軸和短軸來表示瞳孔的大小,並將這兩個參數用作網絡的輸出。關於網絡的輸入,數據集來自視頻(連續幀)。如果從視頻中獲取每一幀並使用它們來訓練CNN模型,則可能會因為圖像太相似而導致過度擬合。為了避免這個問題,本研究使用數據擴充以及計算結構相似度以確保圖像具有一定程度的差異。為了優化網絡結構,本研究使用平均誤差對更改網絡深度和卷積濾波器的視場(FOV)進行了比較。結果表明,加深網絡和加寬卷積濾波器的FOV都可以減小平均誤差。根據結果,瞳孔長度的平均誤差為7.63%,瞳孔面積為14.68%。它可以在每秒36幀的低成本移動嵌入式系統中運行,因此可以將低成本系統用於瞳孔大小預測。
2. 智慧農業
以數據增強法改善深度學習於小物件偵測之正確性:以鳥類偵測為例
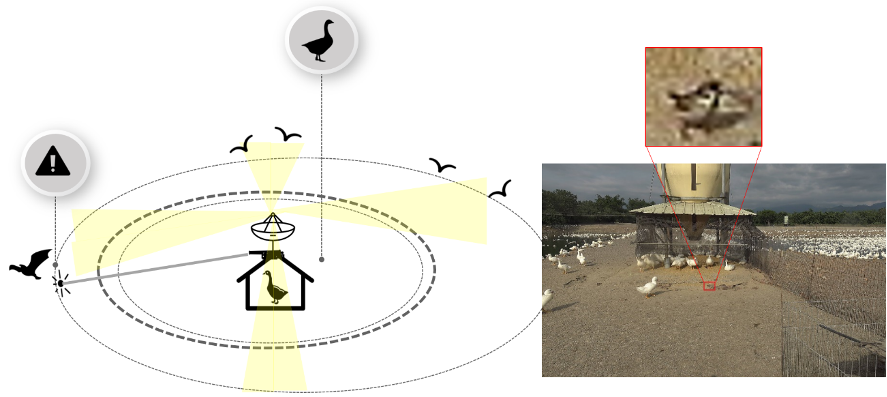
實驗室發展AI自動偵測野鳥技術,整合於飼養場域中並搭配雷射裝置用於驅趕野鳥,以此預防家禽感染禽流感。演算法基於小物件偵測數據增強法、課程學習、困難反例探勘方法進行改良,並改善模型辨識小物件的準確度。於研究中,我們驗證不同方法對相同模型的辨識準確度之改進效果。本研究以鳥類偵測為例,在大量收集鳥類數據後進行驗證,並於實際場域中實現軟硬體設備。
3. 智慧工程
智慧圖紋
本研究基於深度生成網路開發了適用於傢俱、磁磚等產業的圖紋擴增技術。該架構透過學習特定的紋理樣本,來達到自動化生成與原樣本具有視覺相似,但帶有變異及隨機性的紋理。本研究架構如圖1-(a)所示,包含了一個VAE (variational autoencoder)網路與一個GAN(Generative adversarial nets)網路:前者生成粗略紋理,加入了殘差結構(Residual connection)以及批次正規化層(Batch normalization)來加速訓練與提升影像品質。後者以WGAN-GP生成紋理細節。
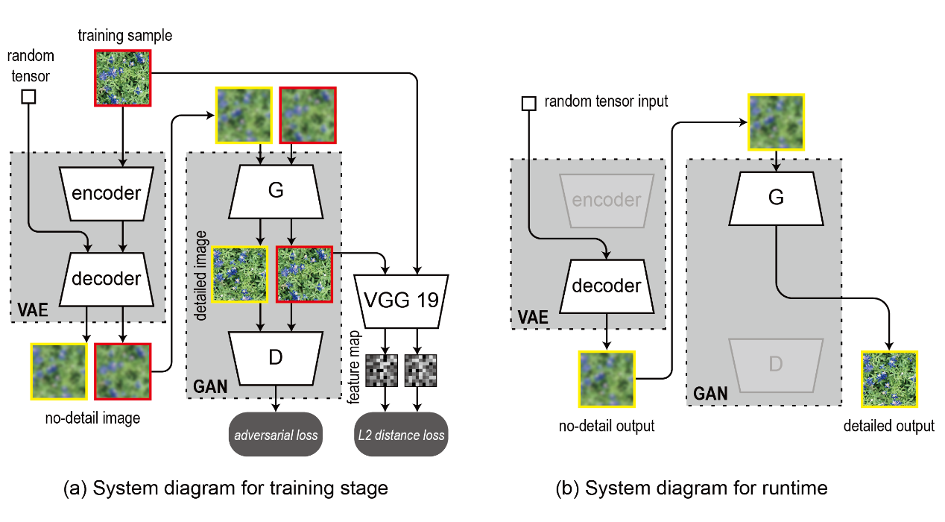
圖1 系統架構
訓練流程如圖1-(a) 所示,由VAE產生兩種影像,一種是經編碼器壓縮、解碼器解壓縮後得到的「重建影像」 (圖中以紅色外框標示);另一種是一符合高斯分佈的隨機張量直接經過解碼器解壓縮所生成的「生成影像」(圖中以黃色外框標示)。對於生成影像,我們將其輸入生成網路來得到細節化的成果,再將該成果輸入判別網路計算損失。而對於重建影像,除了上述的損失,還額外將細節化的成果與原始樣本輸入已訓練好的經典模型VGG19,計算兩者於特徵空間中的差異。實際應用流程如圖1- (b) 所示,僅須透過輸入隨機張量,經由VAE的解碼器與GAN的生成網路,便能夠得到具備高細節的生成影像。
圖2展示了訓練影像(上)與隨機生成的影像(下),可以看到在木紋以及石紋的生成表現,該系統能夠學習各尺度的特徵並用於重構影像產生高仿真的影像。雖然在細節部分無法達到與訓練樣本一樣的細緻,但仍具備了一定的水準及潛力。

圖2 訓練影像與生成影像
智慧顯示
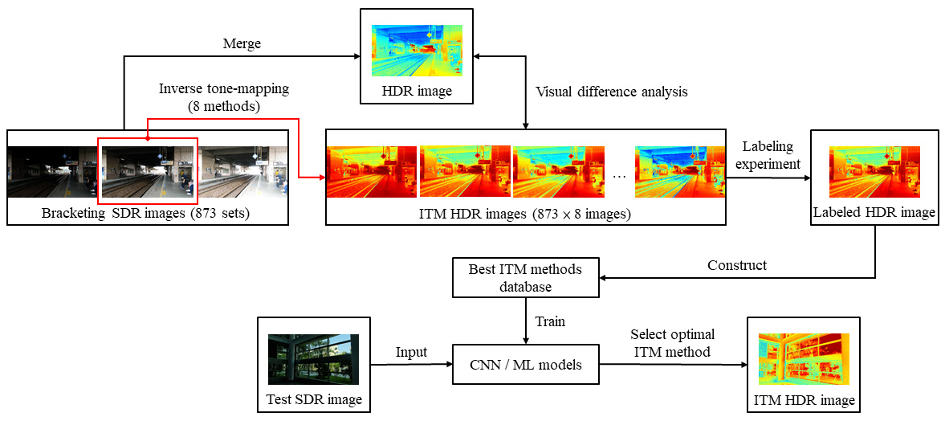
逆色調映射器(Inverse Tone-Mapping Operator, ITMO)能夠將SDR影像的動態範圍擴展至高動態範圍(HDR),幫助佔絕對多數的SDR影像轉換成HDR影像,進而發揮HDR顯示器的性能,提升影像品質。不過現有的數種ITMO是基於不同的理念或目的設計的,不同的影像內容可能分別適用不同的ITMO,因此本研究嘗試結合善於處理影像內容分析的AI技術,建構一套基於監督式學習的最適ITMO預測系統。本研究透過最佳影像標記與等級評價人因實驗,評估8種ITMO,使用6種機械學習方法(SVM, MLP, KNN等)、5種CNN網路架構(VGG16, ResNet-50等)在不同參數下預測最適ITMO的準確度。結果顯示灰度影像訓練的AlexNet模型能準確預測最適逆色調映射器。
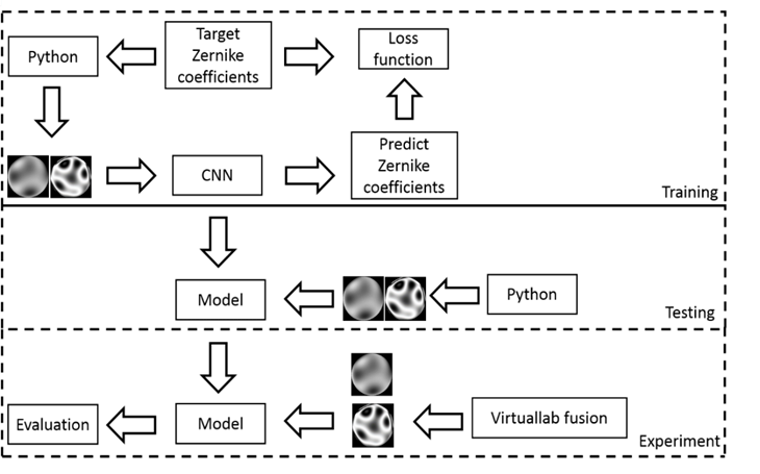
基於卷積神經網絡的干涉條紋和相位圖像差係數預測技術
在這項研究中,我們提出了一種預測光學系統的Zernike係數的新方法。我們通過神經網絡中的圖像識別功能預測Zernike係數。它可以減少干涉儀中常用的數學運算並提高測量精度。我們使用相位圖和干涉條紋作為神經網絡的輸入,分別預測係數並比較兩個模型的效果。在這項研究中,使用python和光學仿真軟件來確認整體效果。結果顯示,所有的均方根誤差(RMSE)都小於0.09,這意味著可以將干涉條紋或相位圖直接轉換為係數。 不僅可以減少計算步驟,而且可以提高整體效率並減少計算時間。例如,我們可以使用它來檢查相機鏡頭的性能。